| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 게임
- 오라클
- 오큘러스
- 영어독해
- 가볼만한곳
- Python
- English Joke
- 골든게이트
- 독해연습
- 체스-TD
- 임바 오토체스
- Imba Auto Chess
- java program
- 게임기
- 영어유머
- Chess-TD
- 모바일레전드
- 관광
- english study
- 왕좌의게임
- 영어공부
- 여행
- Mobile Legends
- 이솝우화
- 영어 유머
- oracle
- MLBB
- 롤
- OGGMA
- 심플한 게임
- Today
- Total
Almost-Native
파이썬에서 Oracle DB 로 대용량 BLOB 데이터 읽기/쓰기하는 샘플 예제 (cx_Oracle 라이브러리 Streaming 방식) 본문
파이썬에서 Oracle DB 로 대용량 BLOB 데이터 읽기/쓰기하는 샘플 예제 (cx_Oracle 라이브러리 Streaming 방식)
2022. 6. 11. 19:40이전 페이지에서 파이썬 cx_Oracle 라이브러리를 이용해서 BLOB 데이터를 오라클DB에 Insert 하고, Select 하는 프로그램을 만들어 봤습니다.
앞에서는 156MB 크기의 동영상 파일을 가지고 테스트했는데, 이 파일의 크기가 1GB 가 넘어가면 이런 방식으로 할 수가 없습니다. 파일크기가 1GB 이상인 경우에는 한번에 처리할 수 없기 때문에 잘라서 등록하고, 조회할 때도 잘라서 조회해야 합니다.
자르지 않고 한번에 처리할려고 하는 경우, 아래와 같은 에러가 발생합니다.
cx_Oracle.DatabaseError: DPI-1057: buffer size of 1710915901 is too large (max 1073741822)
자르는 단위를 chunk 라고 합니다. 이번 실습에서는 1.67GB 의 동영상 파일(1670MB.mkv)을 64KB 단위의 chunk 로 나눠서 BLOB Type 으로 Insert 하고, 이를 다시 조회해서 1670MB_output.mov 동영상 파일로 출력해 보겠습니다.
이렇게 잘라서 처리하는 방식을 Streaming 방식이라고 합니다.
파이썬 소스코드는 아래와 같습니다.
|
import cx_Oracle
# create table BLOB_TBL ( id NUMBER, bb BLOB ) lob (bb) store as SecureFile;
#####################################################################################################
# DB 접속
#####################################################################################################
con = cx_Oracle.connect("scott", "tiger", "192.168.1.171:1521/ORA19", encoding="UTF-8")
cursor = con.cursor()
nKey = 11
num_bytes_in_chunk = 65536
#####################################################################################################
# Insert ( > 1GB )
#####################################################################################################
fr = open('1670MB.mkv', 'rb')
lob_var = cursor.var(cx_Oracle.DB_TYPE_BLOB)
cursor.execute("insert into BLOB_TBL (id, bb) values (:1, empty_blob()) returning bb into :2", [nKey, lob_var])
blob, = lob_var.getvalue()
offset = 1
while True:
blob_data = fr.read(num_bytes_in_chunk)
if blob_data:
blob.write(blob_data, offset)
if len(blob_data) < num_bytes_in_chunk:
break
offset += len(blob_data)
con.commit()
fr.close()
#####################################################################################################
# Select ( > 1GB )
#####################################################################################################
fw = open("1670MB_output.mkv", "wb")
cursor.execute("select bb from BLOB_TBL where id = :1", [nKey])
blob, = cursor.fetchone()
offset = 1
while True:
blob_data = blob.read(offset, num_bytes_in_chunk)
if blob_data:
fw.write(blob_data)
if len(blob_data) < num_bytes_in_chunk:
break
offset += len(blob_data)
fw.close()
con.close()
|
import cx_Oracle
: cx_Oracle 라이브러리를 사용하기 위해서 Import 합니다.
con = cx_Oracle.connect("scott", "tiger", "192.168.1.171:1521/ORA19", encoding="UTF-8")
: Oracle DB 에 접속하기 위해서 DB User, Password 와 접속할 DB 의 IP, Port, Service명 등의 정보가 필요합니다.
Port, 서비스명을 모르는 경우, 해당 DB 서버에서 lsnrctl status 커맨드로 확인할 수 있습니다.
nKey = 11
num_bytes_in_chunk = 65536
: nKey 는 나중에 BLOB_TBL 테이블에서 조회할 때 사용하기 위한 조회키값입니다. 11로 지정했습니다.
파일을 잘라서 처리하기 위한 chunk size 로 65536 값을 지정합니다.
★ chunk size 는 자유롭게 조정할 수 있는데, 테스트결과 chunk size 를 크게 잡아주는게 성능에 더 유리합니다.
ex) num_bytes_in_chunk = 1073741822
1073741822 는 대략 1GB 정도이고, Streaming 방식을 쓰지 않을때 처리할 수 있는 최대크기로
64KB 로 지정했을때보다 빠릅니다.
fr = open('1670MB.mkv', 'rb')
: 1670MB.mkv 동영상 파일을 오픈합니다.
lob_var = cursor.var(cx_Oracle.DB_TYPE_BLOB)
cursor.execute("insert into BLOB_TBL (id, bb) values (:1, empty_blob()) returning bb into :2", [nKey, lob_var])
blob, = lob_var.getvalue()
: Insert DML SQL 을 실행합니다. 그런데, lob_var 변수에 계속 데이터를 Writing 할 수 있는 포인터를 넘기는 부분이 이전과 다릅니다.
while True:
blob_data = fr.read(num_bytes_in_chunk)
if blob_data:
blob.write(blob_data, offset)
if len(blob_data) < num_bytes_in_chunk:
break
offset += len(blob_data)
: 루핑을 돌면서 chunk 단위(64KB)씩 파일에서 읽어서 blob.write 를 반복수행합니다.
fw = open("1670MB_output.mkv", "wb")
: 출력할 동영상 파일을 생성하고 오픈합니다.
cursor.execute("select bb from BLOB_TBL where id = :1", [nKey])
blob, = cursor.fetchone()
: BLOB 타입인 bb 컬럼의 데이터를 읽어서 BLOB Type 변수 blob 에 넘깁니다.
while True:
blob_data = blob.read(offset, num_bytes_in_chunk)
if blob_data:
fw.write(blob_data)
if len(blob_data) < num_bytes_in_chunk:
break
offset += len(blob_data)
: 루핑을 돌면서 blob 에서 chunk 단위(64KB)로 읽어서 파일에 Writing 합니다.
실행결과는 아래와 같습니다.

첫번째 조회시(프로그램 실행전)에는 조회되는 건이 없고,
두번째 조회시(프로그램 실행후)에는 1건이 조회되는 것을 확인할 수 있습니다.
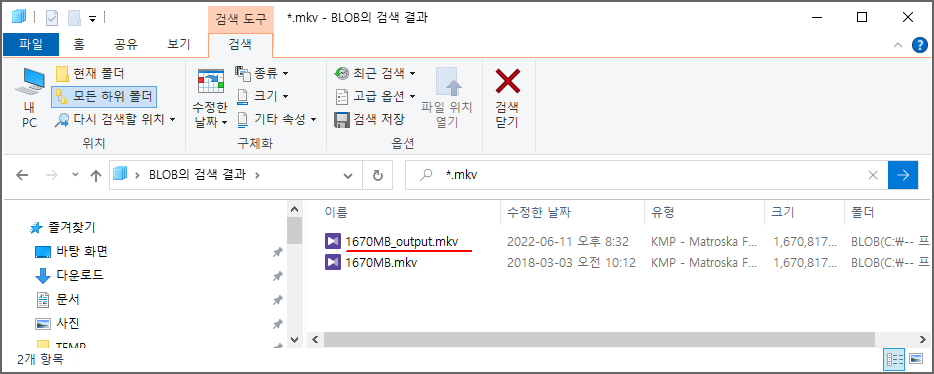
탐색기에서 확인해보면, 처음에는 1670MB.mkv 파일만 존재했었고,
프로그램 실행후, 1670MB_output.mkv 파일이 생성된 것을 확인할 수 있습니다.
'Java 프로그램 개발, IT' 카테고리의 다른 글
| 파이썬에서 Oracle DB 로 대용량 BLOB 데이터 읽기/쓰기하는 샘플 예제 (oracledb 라이브러리 Streaming 방식) (0) | 2022.06.11 |
|---|---|
| 파이썬에서 Oracle DB 로 BLOB 데이터 읽기/쓰기하는 샘플 예제 (oracledb 라이브러리 이용) (0) | 2022.06.11 |
| 파이썬에서 Oracle DB 로 BLOB 데이터 읽기/쓰기하는 샘플 예제 (cx_Oracle 라이브러리 이용) (0) | 2022.06.11 |
| 파이썬에서 Oracle DB 접속하여 데이터 읽기/쓰기하는 방법 설명 및 샘플예제 (0) | 2022.06.11 |
| Oracle Database 버전별 Windows OS 설치가능 버전 정리 (0) | 2022.05.06 |



